Glass Slipper lets Claude offload work to a local model. The right-sized one for your Mac. No tinkering with temperature, quantization, or top_k. It just works.
No telemetry. No auto-update.
Glass Slipper is new. Send me feedback! robertkarljr at the big Google mail provider.
v0.1.9 · macOS (Apple Silicon)
Download Glass Slipper v0.1.9.dmgApproximately one email per month. Release notes, what I'm working on next.
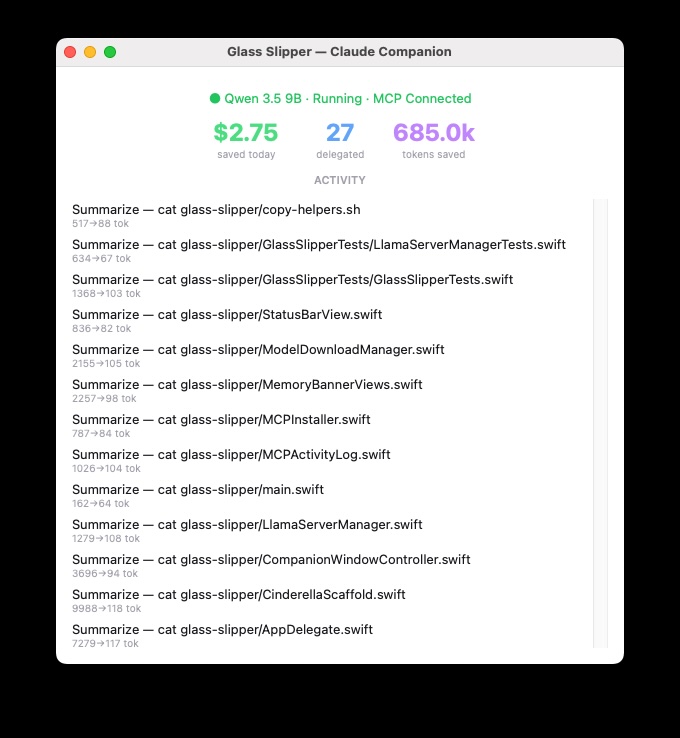
Glass Slipper installs an MCP server that tells Claude it can save tokens by delegating tasks to a local model. When Claude decides a task is a good fit, it calls one of the MCP server's tools instead of doing the work itself.
Under the hood, the following are all distributed in the .app bundle (in the disk image above):
local_summarize, local_explain, and local_review to Claude.